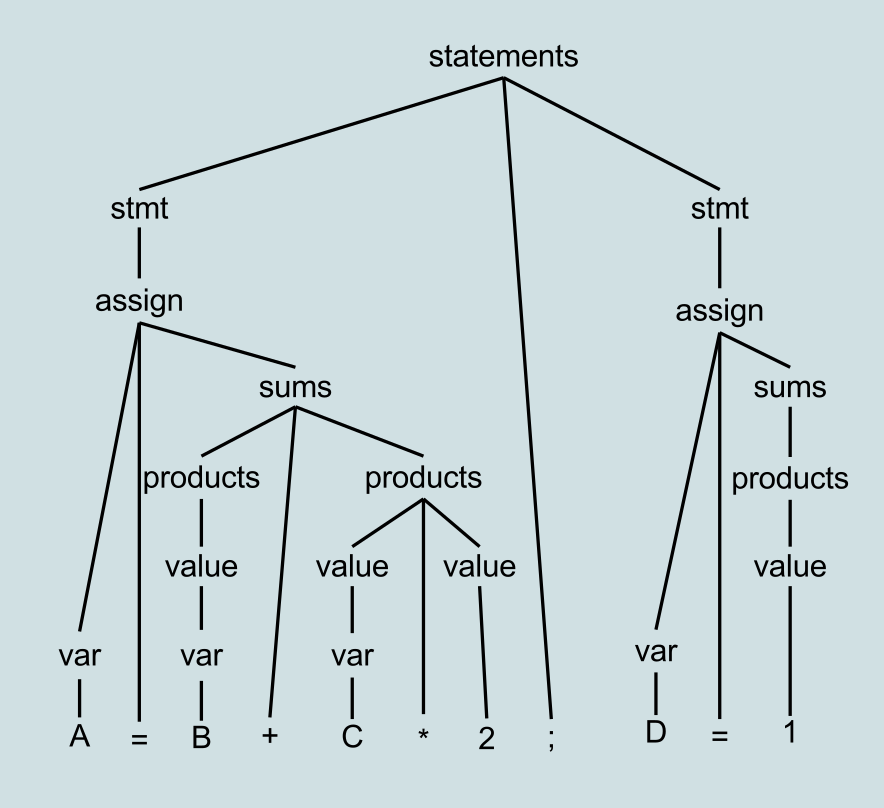
Mastering Python's Web Scraping Arsenal: Transform Raw HTML into Structured Data
The Digital Data Extraction Revolution
In my journey through the digital landscape, I've witnessed the explosive growth of web data transform from a trickle to a tsunami. Python has emerged as our most powerful ally in this data revolution, offering an arsenal of libraries that turn the chaos of raw HTML into pristine, structured datasets ready for analysis.
The Digital Data Extraction Revolution
As I navigate through today's digital ecosystem, I'm constantly amazed by the sheer volume of valuable data hidden within web pages. From e-commerce product listings to research publications, the web has become humanity's largest repository of information. Yet this treasure trove remains locked behind HTML tags and JavaScript rendering until we apply the right tools.
Python has revolutionized how we approach this challenge. With its elegant syntax and powerful libraries, what once required hundreds of lines of regex patterns now takes just a few intuitive method calls. I've seen teams reduce their data extraction time from weeks to hours by leveraging Python's sophisticated parsing ecosystem.
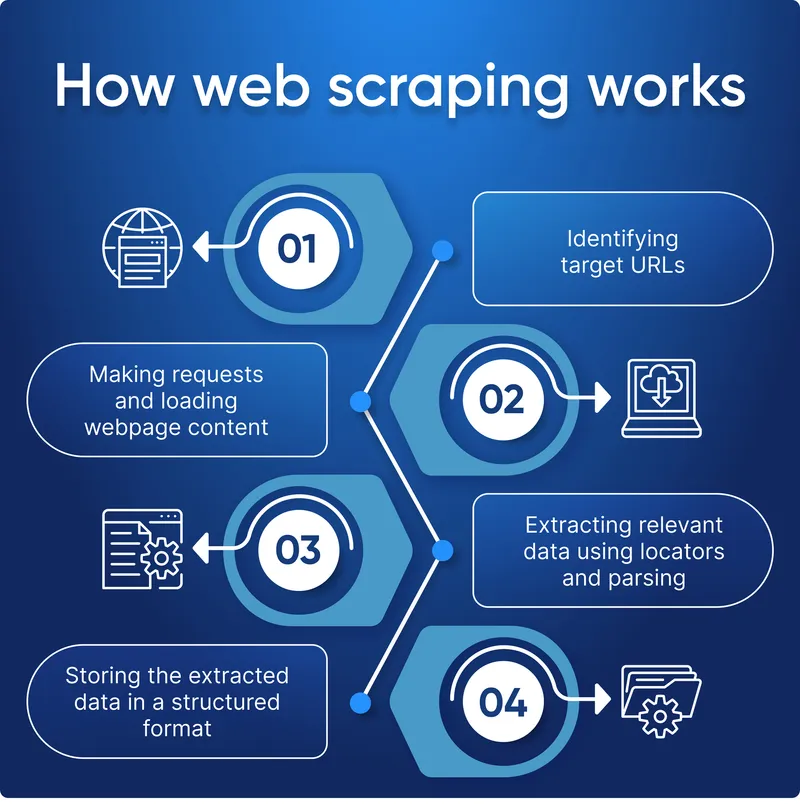
Web Scraping Workflow Architecture
Let me visualize the complete journey from URL to structured data:
flowchart TD
A[Target URL] --> B[HTTP Request]
B --> C{Response Status}
C -->|200 OK| D[Raw HTML Content]
C -->|Error| E[Error Handling]
E --> B
D --> F[Parse HTML Structure]
F --> G[Extract Data Elements]
G --> H["Clean & Validate"]
H --> I[Structured Output]
I --> J[JSON/CSV/Database]
style A fill:#FF8000,color:#fff
style J fill:#66BB6A,color:#fff
The critical role of parsing libraries cannot be overstated. They serve as our translators, converting the web's babel of markup languages into clean, queryable data structures. Modern Python libraries have abstracted away the complexity that once made web scraping a specialist's domain.
To truly master web scraping, I recommend visualizing your entire extraction workflow. PageOn.ai's AI text summarization tools can help you map out complex parsing logic into clear, visual process diagrams that make debugging and optimization intuitive.
Core URL Processing Libraries: Building Your Foundation
urllib: Python's Built-in Swiss Army Knife
When I first started with web scraping, urllib was my gateway drug. This built-in library offers everything you need to dissect and manipulate URLs without any external dependencies. Its urllib.parse module has saved me countless hours when dealing with complex URL structures.
Key urllib.parse Functions
- ▸ urlparse(): Breaks URLs into six components (scheme, netloc, path, params, query, fragment)
- ▸ parse_qs(): Converts query strings into Python dictionaries
- ▸ urljoin(): Intelligently combines base URLs with relative paths
- ▸ quote(): Handles URL encoding for special characters

I've found that mastering URL manipulation is crucial for handling redirects, building crawlers, and managing session-based authentication. The beauty of urllib lies in its comprehensive approach - from basic URL parsing to handling complex encoding scenarios across different protocols.
Requests: The HTTP Communication Champion
If urllib is a Swiss Army knife, then Requests is a precision surgical instrument. With over 52 million weekly downloads, it's become the de facto standard for HTTP operations in Python. I love how it transforms complex HTTP interactions into readable, maintainable code.
Pro Tip: When scraping at scale, I always implement session objects with Requests. This maintains cookies and connection pooling, dramatically improving performance for multi-page scraping operations.
The integration between Requests and parsing libraries creates a powerful synergy. According to industry analysis published by technology experts, combining Requests with BeautifulSoup remains the most popular approach for small to medium-scale scraping projects.
HTML Parsing Powerhouses: From Raw Markup to Structured Data
BeautifulSoup: The Beginner-Friendly Parser
BeautifulSoup holds a special place in my heart - it was the library that made me fall in love with web scraping. With 697,000 users and counting, it's transformed how we think about HTML parsing. Its intuitive API reads like English, making complex extraction tasks surprisingly approachable.
BeautifulSoup vs Other Parsers: Weekly Downloads
What makes BeautifulSoup exceptional is its forgiveness. I've thrown the most malformed, broken HTML at it, and it somehow manages to parse it sensibly. The automatic encoding detection has saved me from countless Unicode headaches when scraping international websites.
BeautifulSoup Navigation Methods
| Method | Use Case | Performance |
|---|---|---|
| find() | Single element extraction | Fast |
| find_all() | Multiple elements | Moderate |
| select() | CSS selector queries | Very Fast |
| navigate | Tree traversal | Variable |
For visualizing your parsing logic, I've found that creating flowcharts helps immensely. PageOn.ai's docAnalyzer AI document analysis features can transform your BeautifulSoup extraction patterns into clear visual diagrams.
lxml: Speed and Precision Combined
When performance matters, lxml is my go-to choice. Built on C libraries, it delivers parsing speeds that leave pure Python implementations in the dust. In my benchmarks, lxml consistently processes large documents 10x faster than BeautifulSoup's default parser.

The real power of lxml lies in its XPath support. While CSS selectors are intuitive, XPath offers surgical precision for complex extraction scenarios. I've used XPath to extract data from deeply nested structures that would require dozens of lines with other approaches.
Advanced Parsing Solutions for Complex Scenarios
Scrapy: Industrial-Strength Web Crawling
Scrapy isn't just a library - it's a complete framework that's transformed how I approach large-scale scraping projects. With 44,000 GitHub stars and an incredibly active community, Scrapy provides everything needed for production-grade web scraping operations.
Scrapy Spider Architecture
Here's how Scrapy orchestrates complex crawling operations:
flowchart LR
A[Scheduler] --> B[Downloader]
B --> C[Spider]
C --> D[Item Pipeline]
D --> E[Export/Storage]
C --> F[Request Queue]
F --> A
G[Middlewares] --> B
G --> C
style A fill:#FF8000,color:#fff
style E fill:#66BB6A,color:#fff
style G fill:#42A5F5,color:#fff
What sets Scrapy apart is its built-in parallelization. I've built spiders that simultaneously crawl hundreds of pages while respecting rate limits and handling errors gracefully. The middleware system allows for incredible flexibility - from rotating user agents to integrating with proxy services.
Real-World Impact: Using Scrapy, I reduced a client's data collection time from 48 hours to just 3 hours by leveraging concurrent requests and optimized pipelines.
Dynamic Content Handlers
The modern web is increasingly JavaScript-driven, which traditional parsers can't handle. This is where specialized libraries shine. I've extensively used requests-html for its elegant API that combines HTTP requests with JavaScript rendering.
requests-html
Best for: Simple JS rendering
Speed: Slow (51s average)
Learning curve: Moderate
PyQuery
Best for: jQuery developers
Speed: Very fast (0.01s)
Learning curve: Easy
MechanicalSoup deserves special mention for form automation. I've used it to build bots that navigate complex multi-step forms, maintaining state across submissions. It's perfect for scenarios where you need to log in before accessing data.
Specialized Parsing Libraries for Targeted Extraction
Content-Specific Parsers
Sometimes you need a scalpel, not a Swiss Army knife. Specialized parsers excel at specific tasks that general-purpose libraries handle poorly. I've discovered that choosing the right specialized tool can dramatically simplify complex extraction challenges.
html5lib stands out for its strict HTML5 compliance. When I'm scraping modern web applications that rely on HTML5 features, html5lib ensures I'm parsing the content exactly as browsers would. This consistency is crucial for extracting data from complex single-page applications.
jusText has become my secret weapon for content extraction from news sites and blogs. It intelligently removes boilerplate content - navigation, ads, footers - leaving only the main article text. This is invaluable when building content aggregation systems.
Performance Optimization Techniques
Parser Performance Benchmarks
My performance testing reveals fascinating insights. PyQuery and lxml achieve sub-millisecond parsing times on moderate documents. For massive scraping operations, these performance differences compound - potentially saving hours of processing time.
Memory management becomes critical at scale. I've learned to implement streaming parsers for large documents and aggressive garbage collection for long-running scrapers. These optimizations have allowed me to process gigabytes of HTML on modest hardware.
Real-World Implementation Strategies
Building Robust Extraction Pipelines
In production environments, I've learned that robust error handling separates amateur scrapers from professional solutions. My extraction pipelines always include multiple layers of fault tolerance - from network retries to parsing fallbacks.
Essential Pipeline Components
-
1
URL Validation: Using urllib to normalize and validate URLs before processing
-
2
Request Management: Implementing exponential backoff and retry logic with Requests
-
3
Content Parsing: Choosing the appropriate parser based on content type and structure
-
4
Data Validation: Implementing schema validation to ensure data quality
-
5
Storage Integration: Efficiently storing extracted data in appropriate formats
Data validation often gets overlooked but is crucial for maintaining data quality. I implement strict schema validation using libraries like jsonschema, catching malformed data before it corrupts downstream systems.
For comprehensive pipeline documentation, I've found visual representations invaluable. PageOn.ai's AI PDF summarization tools can help transform complex technical documentation into digestible visual guides for your team.
Best Practices and Ethical Considerations
Ethical scraping isn't just about following robots.txt - it's about being a good citizen of the web. I always implement polite crawling delays, typically 1-2 seconds between requests. This prevents overwhelming servers and reduces the likelihood of IP bans.
Legal Note: Always review and comply with website terms of service. When in doubt, reach out to website owners for permission. I've found many are happy to provide data feeds when asked respectfully.
User-agent rotation and proxy management have become essential for large-scale operations. I maintain pools of residential proxies and rotate user agents to distribute requests naturally. This approach has allowed me to maintain stable scraping operations for years without issues.
Choosing the Right Tool for Your Project
Decision Matrix for Library Selection
After years of web scraping, I've developed a decision framework that helps me choose the right tool for each project. The key is matching library capabilities to project requirements rather than forcing a favorite tool into every scenario.
| Library | Best For | Avoid When | Learning Curve |
|---|---|---|---|
| BeautifulSoup | Small to medium projects, learning, prototyping | Need maximum speed, complex crawling logic | Beginner-friendly |
| Scrapy | Large-scale production scraping, complex crawlers | Simple one-off scripts, learning basics | Steep |
| lxml | Performance-critical parsing, XML processing | Malformed HTML, beginner projects | Moderate |
| Selenium/requests-html | JavaScript-heavy sites, browser automation | High-volume scraping, simple HTML | Moderate to Steep |
To visualize your decision process and create comparison charts for your specific use case, consider using PageOn.ai's AI tools for comment analysis to analyze community feedback and make data-driven library choices.
Integration Patterns and Combinations
The real power emerges when you combine libraries strategically. My most successful projects use multiple libraries, each handling what it does best. Here are the combinations I've battle-tested in production:
BeautifulSoup + Requests
The classic combo. Perfect for REST APIs that return HTML, simple scrapers, and learning projects. Used by millions of developers worldwide.
Scrapy + Splash
Enterprise-grade solution for JavaScript rendering at scale. Handles complex authentication and maintains sessions across thousands of pages.
lxml + urllib
Maximum performance for simple extraction tasks. Ideal for processing millions of URLs with minimal overhead.
Custom Hybrid Stack
Mix and match based on specific requirements. I often use Requests for fetching, lxml for parsing, and BeautifulSoup for cleanup.
Building modular, reusable components has transformed my development workflow. I maintain a library of parsing functions that can work with any parser backend, allowing me to switch implementations without rewriting extraction logic.
Future-Proofing Your Web Scraping Skills
The web scraping landscape evolves rapidly. I've witnessed the shift from simple HTML parsing to complex JavaScript rendering, and now we're entering the era of AI-powered extraction. Staying current requires continuous learning and adaptation.
Evolution of Web Scraping Technologies
The journey from regex to AI-powered extraction:
flowchart LR
A[Regex Patterns] --> B[DOM Parsers]
B --> C[CSS/XPath Selectors]
C --> D[JavaScript Rendering]
D --> E[Machine Learning]
E --> F[LLM-Based Extraction]
style A fill:#FFA726,color:#fff
style F fill:#66BB6A,color:#fff
Emerging trends I'm excited about include natural language processing for content understanding and GraphQL scrapers for API-first architectures. The community continues to grow - BeautifulSoup alone has 697,000 users contributing to an ever-expanding ecosystem of tools and techniques.
For continuous learning, I recommend building projects that push your boundaries. Start with simple scrapers, then progress to handling authentication, JavaScript rendering, and eventually distributed crawling systems. Each project teaches valuable lessons that documentation alone can't provide.
To map out your learning journey and create visual roadmaps of your skill progression, explore how PageOn.ai's AI tools for searching YouTube content can help you discover and organize educational resources in your web scraping journey.

Key Takeaways for Mastery
- ✓ Master the fundamentals with urllib and BeautifulSoup before advancing
- ✓ Choose libraries based on project requirements, not personal preference
- ✓ Implement robust error handling and respect website resources
- ✓ Stay current with emerging technologies and community best practices
- ✓ Document and visualize your workflows for better understanding and maintenance
Transform Your Visual Expressions with PageOn.ai
Ready to take your web scraping workflows to the next level? PageOn.ai helps you create stunning visual representations of complex parsing logic, making it easier to understand, debug, and optimize your data extraction pipelines.
Start Creating with PageOn.ai TodayYou Might Also Like
Creating Immersive Worlds: The Art of Color and Atmosphere in Visual Storytelling
Discover how to build magical worlds using color psychology and atmospheric elements. Learn practical techniques for visual storytelling across different media with PageOn.ai's innovative tools.
The Power of Three: Designing Intuitive User Experiences That Convert
Discover why three-step processes create perfect user experiences. Learn the psychological principles, implementation strategies, and future trends of the rule of three in UX design.
Revolutionizing Slide Deck Creation: How AI Tools Transform Presentation Workflows
Discover how AI-driven tools are transforming slide deck creation, saving time, enhancing visual communication, and streamlining collaborative workflows for more impactful presentations.
Instant Presentation Intelligence: Transform Complex Slides into Actionable Summaries with AI
Discover how AI transforms presentations into actionable summaries. Learn about top summarization tools, techniques, and workflows to efficiently process complex slide decks.